
For years, the promise of AI customer service has been clear: reduce cost-to-serve, improve CSAT, and deliver personalized experiences at scale.
And that promise is real. AI customer service agents are now autonomously resolving complex conversations across email, messaging, and voice. Enterprises are automating high-volume workflows and expanding coverage across channels and languages.
But as AI agents take on more responsibility, a new challenge emerges.
It isn’t capability. It’s confidence.
AI customer service doesn’t fail because the technology can’t reason. It fails when enterprises lack a structured, scalable way to validate how their AI agent behaves as it evolves.
Without structured testing, improvement becomes risky. And risk slows progress.
The next phase of enterprise AI customer service isn’t about adding more channels or deploying more automation. It’s about managing intelligence with discipline.
In this post, we’ll explore why traditional QA breaks under AI, how leading enterprises evaluate AI agent performance at scale, and what structured testing changes when automation becomes mission-critical.

The confidence gap in AI customer service
Modern AI customer service agents don’t follow rigid scripts. They reason dynamically.
They interpret intent, retrieve structured data, apply policy logic, execute multi-step workflows, and adapt responses in real time. That flexibility is what makes conversational AI for customer service powerful.
It’s also what makes it difficult to evaluate.
Even small updates—a revised refund policy, a new knowledge article, a prompt adjustment, or an updated Playbook—can subtly shift behavior. A change intended to improve one scenario may unintentionally introduce regressions in another.
Many enterprises discover those shifts reactively:
- A spike in escalations
- A drop in CSAT
- A compliance concern raised after deployment
- A workflow failing under edge-case conditions
At that point, teams are combing through live conversations to understand what changed—investigating after customers have already been affected.
This reactive posture slows iteration, increases operational risk, and erodes confidence in automation. Instead of proactively improving AI customer service, teams are defending it.
That’s not scalable. And it’s not sustainable.
Why traditional QA breaks at scale
Manual QA was built for scripted systems. It works when flows are deterministic. When you know exactly which path will fire. When logic branches are limited and predictable.
AI agents don’t behave that way.
They reason based on context, choose actions dynamically, and adapt responses based on customer data, conversation history, and even language preferences across regions. That means:
- You can’t manually test every scenario.
- You can’t reliably predict every edge case.
- You can’t depend on reviewing conversations after the fact to catch issues early.
As AI customer service expands across channels, including voice, the stakes rise even further. Real-time conversations leave no buffer for inconsistent logic or policy drift.
The result is a hidden operational risk. Without structured validation, enterprises face:
- Undetected regressions in critical workflows
- Compliance or policy drift over time
- Inflated resolution metrics that mask quality gaps
- Increased escalation volume
- Reduced executive confidence in automation
Because AI agents reason dynamically, small configuration changes can produce unintended behavior shifts across workflows, customer attributes, or channels. Without structured validation, enterprises are effectively experimenting in production manually each time. With it, they protect customer experience while continuously improving automation at scale.
Is your enterprise ready for AI customer service?
Before choosing the right AI customer service solution for enterprise scale, it’s important to understand where the organization is at now. This assessment helps you answer that question with clarity and chart the right course forward.
Get the assessmentHow enterprises evaluate AI impact on customer experience
Enterprises evaluating AI customer service platforms often ask: How do we objectively measure AI agent performance as it evolves?
Leading organizations don’t rely solely on downstream metrics like CSAT or escalation rate. They define critical scenarios in advance, establish measurable success criteria, simulate responses at scale, and track expected outcomes over time to detect regressions and validate improvements.
The answer isn’t just better models. It’s operational discipline.
At Ada, we call this the Agentic Customer Experience (ACX) Operating Model, a structured approach to scaling AI customer service that combines platform capabilities, governance practices, and expert oversight. It treats AI not as a feature, but as a managed system.
To improve customer service efficiency with AI, organizations need four things:
- Clearly defined expectations for AI behavior
- Repeatable testing across critical customer journeys
- Objective evaluation criteria
- Continuous validation over time
Without that structure, AI becomes reactive. Teams ship changes and wait to see what happens.
With structure, AI becomes measurable, governable, and continuously improvable. That’s the difference between experimentation and enterprise AI customer service.

From reactive QA to structured validation
Enterprise AI customer service requires a shift, from manual, one-off testing to automated, repeatable evaluation. From reactive monitoring to proactive governance. And from intuition to evidence.
Structured testing means defining critical customer scenarios in advance—like refund eligibility, delivery updates, policy explanations, or compliance-sensitive responses—and clearly outlining what “good” looks like.
For example, let’s say a customer requests a refund for a cancelled booking. The expected outcomes are:
- The AI agent confirms refund eligibility
- It clearly states the refund timeline
- It does not imply the refund has already been processed
Those expectations become measurable criteria. Instead of hoping the AI behaves correctly, enterprises validate it at scale.
Testing at Scale
Testing at Scale is Ada’s bulk testing capability that enables enterprises to simulate predefined customer scenarios and automatically evaluate how their AI agent responds—both before updates go live and continuously over time as performance evolves.
AI Managers define test cases, establish clear expected outcomes, and run hundreds of test runs against the live AI agent. Each response is automatically evaluated against those outcomes, producing structured pass/fail results with a rationale summary.
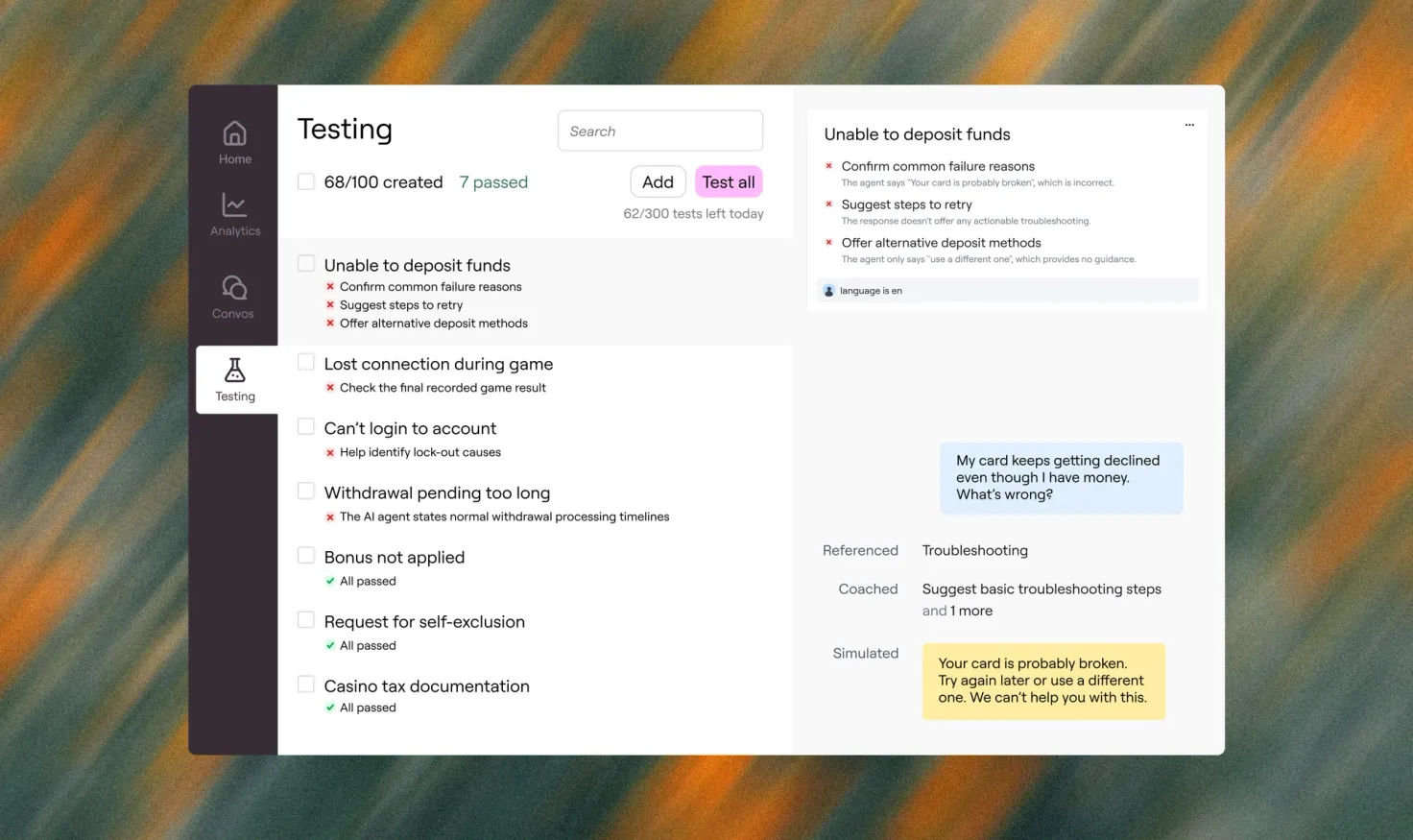
It enables AI Managers to:
- Define clear expected outcomes for each scenario
- Automatically evaluate responses against defined expectations
- Receive structured pass/fail results with a rationale summary
Rather than manually reviewing conversations, teams can simulate how their live AI agent responds across critical journeys in bulk. This transforms how AI customer service is managed.
Instead of discovering regressions after customers are impacted, teams proactively validate behavior and measure performance shifts over time. Testing at Scale doesn’t replace human oversight. It strengthens it, and creates a repeatable benchmark for AI agent performance.

The benefits of Testing at Scale for AI customer service teams
A unified reasoning layer doesn’t just simplify architecture. It changes how teams operate day to day: how they design workflows, enforce policy, measure performance, and improve over time.
The shift isn’t technical. It’s organizational.
For AI Managers
Testing at Scale provides clear visibility into how updates affect AI agent behavior. Instead of combing through conversation logs, managers can:
- Detect regressions early
- Validate improvements objectively
- Identify failing scenarios quickly
- Iterate faster with guardrails
This directly improves customer service efficiency. Instead of spending hours manually reviewing conversations or reacting to escalations, teams focus on targeted improvements backed by clear signals. Iteration accelerates. Risk decreases. And AI coverage expands with confidence.
For CX leaders
Testing at Scale provides executive-level visibility into how AI performance trends over time. Instead of relying on anecdotal feedback or lagging CSAT scores, leaders can:
- See how AI quality evolves across releases
- Quantify the business impact of improvements
- Align AI performance to customer experience standards
- Confidently expand automation without sacrificing quality
This shifts AI from an operational experiment to a measurable growth lever. Decisions become proactive instead of reactive. Investment conversations are grounded in performance data, not intuition. And automation scales in a way that protects both brand trust and customer satisfaction.
For executive stakeholders
Testing at Scale provides enterprise-level assurance that AI investments are delivering measurable returns. Instead of relying on surface-level automation metrics or isolated performance snapshots, executives can:
- Mitigate brand and compliance risk proactively
- Tie automation gains directly to stronger brand loyalty, higher CSAT, and measurable increases in customer lifetime value
- Scale AI initiatives with governance built in
This reframes AI from a tactical tool to a controlled, compounding asset. Risk is managed before it becomes visible to customers. And expansion happens deliberately, with confidence that quality, compliance, and brand standards remain intact.
How leading brands expand without breaking CX
Your AI agent should deliver the same great experience, no matter the channel. In Part 1 of this webinar series, learn how leading brands deliver consistent, connected service across voice, chat, email, social and more.
Watch on-demandAI customer service is an operating discipline
The question is no longer whether conversational AI for customer service works. It does. The real question is whether your organization can operate it systematically, responsibly, and at scale.
High-performing AI customer service isn’t defined by how many channels you deploy. It’s defined by how rigorously you manage intelligence. Governance is what separates experimentation from execution. And AI customer service fails when governance lags behind capability.
Structured testing closes that gap.
It transforms AI from a collection of deployments into a disciplined operating model, one built on validation, visibility, and continuous improvement. When enterprises validate AI agent behavior proactively—not reactively—they reduce operational risk, protect customer experience, and accelerate automation with confidence.
This is how enterprises move beyond experimentation, by managing it deliberately.
Because scaling AI isn’t just about adding capability. It’s about operating it with discipline. That’s the shift from automation to operational excellence.
Start testing at scale
Testing at Scale enables AI Managers to understand how configuration changes impact AI Agent behavior. By creating and running test cases, you can verify that updates improve behavior without causing regressions.
Learn more