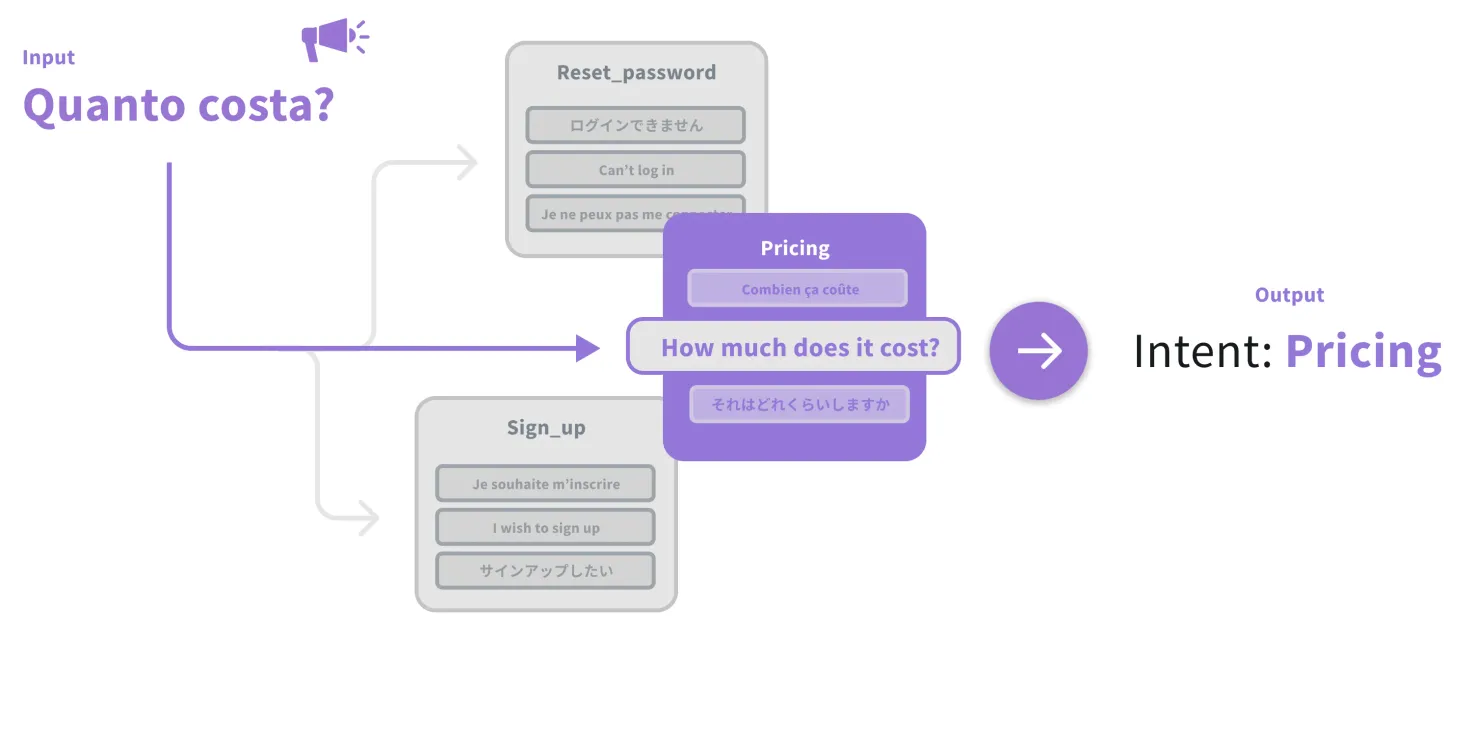
We can’t emphasize this enough: the key to providing a truly VIP experience to everyone your business cares about relies on your ability to interact with them anytime, anywhere — on the channels they prefer and in the languages they speak. So it’s no surprise that building multilingual conversational AI is a top priority for brands today.
This, however, has been challenging. CX teams want to offer localized content in relevant languages. Still, in many cases, this means doubling their investments in the training dataset and content of their current conversational AI solution (or chatbot.)

But as automated brand interactions mature to meet evolving customer expectations, so does the underlying technology that powers them. Today, conversational AI solutions with multilingual functionality are built with one of three approaches to Natural Language Understanding (NLU):
- Translation-based
- Language-specific
- Language-agnostic
Join me for a deep dive into each approach — the intricacies, pros, and cons — to better understand how best-in-class multilingual interactions are built and improved over time.
translation-based NLU
This is the most common, but perhaps not most effective, approach to building multilingual chatbots. The architecture is straight to the point.
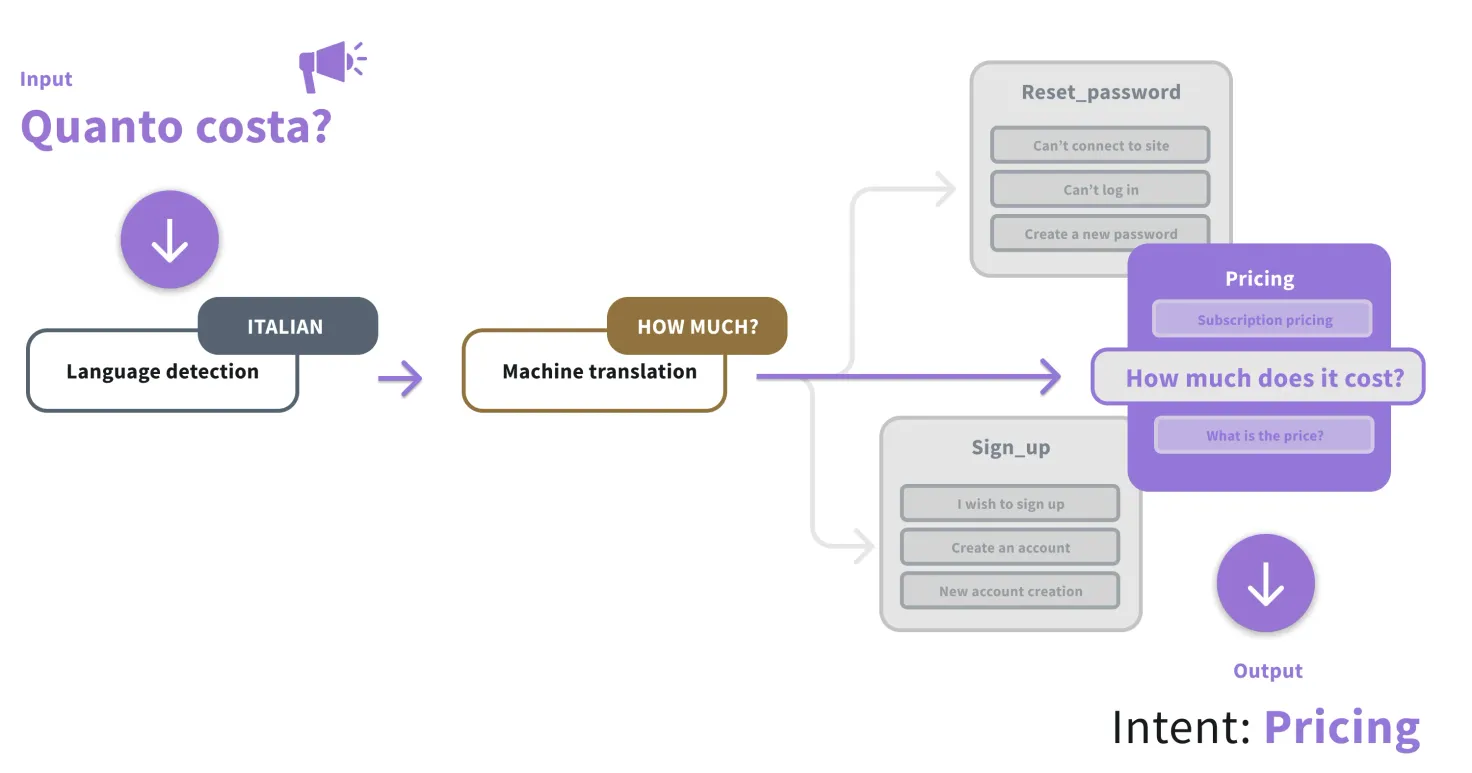
You build and train a bot in one language, then add a step that sends chatter messages in other languages through a third-party machine translation (MT) service like Google Translate. The service translates the message into the language that the NLU model was trained in — usually English — and sends it off for processing. By adding this step, you can use the bot for most languages that the MT engine supports.
pros
There’s a general perception in the market that MT performs poorly for intent classification — the capacity of a bot to “understand” what a chatter is saying by matching the utterance to an intent based on the training it was provided. Our experiments have shown that this isn’t the case, generally, and it does provide a strong prediction baseline across languages.
Additionally, the choice of MT engine has little to no impact on the classification task, since MT is a fairly mature field. Builders could use any MT engine they want. We ran experiments on dozens of MT engines using 16 languages, and they all demonstrated roughly the same capacity for intent classification, within a margin of <1%.
For intent classification specifically, MT will get you up and running with minimal upfront costs. But things get a bit more complicated when maintaining the bot and adding multilingual training data.
cons
When using translation-based NLU bots, the most prominent problem bot builders face is improving answer training and dealing with not understood questions. The reason is simple: translation-based NLU fails when the translation service translates incorrectly.
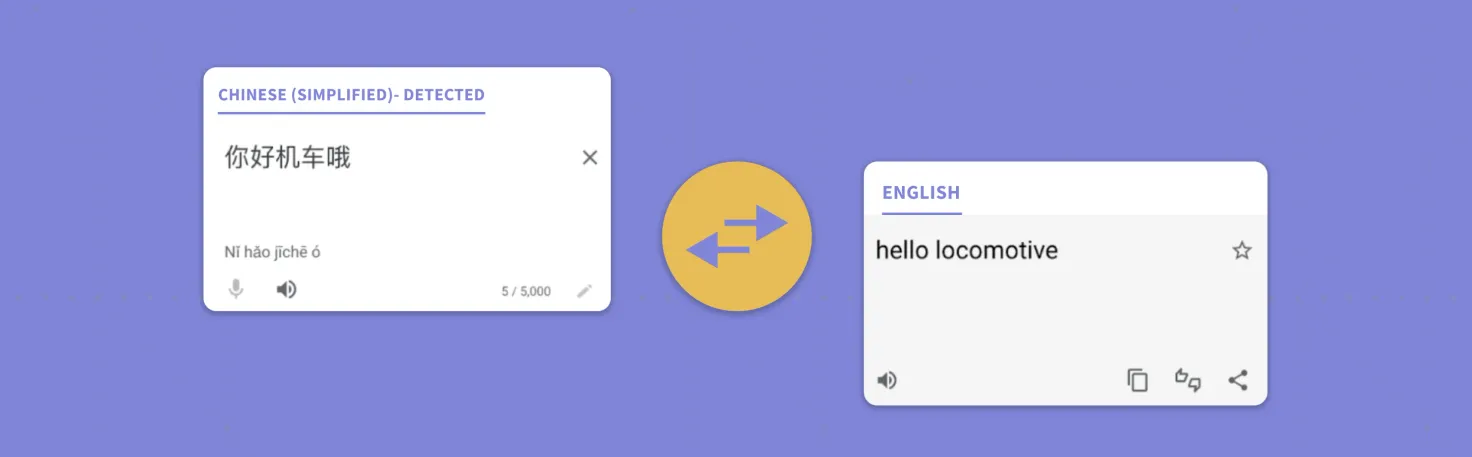
In the example above, “你好机车哦” actually means “you’re so stubborn/annoying,” not “hello locomotive.” The latter is a literal translation of 你好 = hello, 机车 = car, and 哦 = an interjection in Chinese. If you were to train an intent to capture frustrated Chinese-speaking customers, you might need to add “hello locomotive” to your training data.
In cases like this, the most straightforward workaround is to add the poorly generated translation directly to the training set. This has the obvious downside of leading to potentially more significant confusion for the NLU model, which lowers the answer detection performance of the bot.
With this approach, you are limited by the performance of your MT engine and can’t directly benefit from the multilingual content found in chat transcripts or knowledge bases.
language-specific NLU
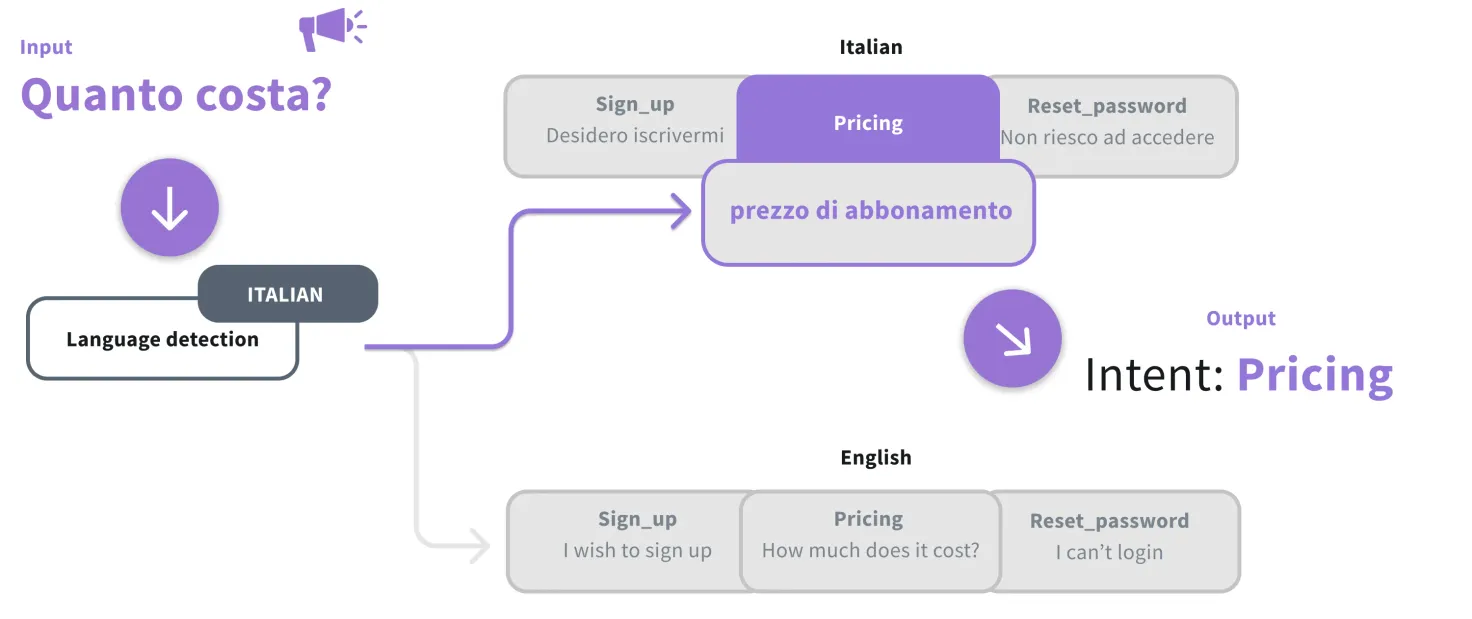
Language-specific NLU has been the go-to solution for building multilingual chatbots without relying on translations thus far. The approach is intuitive — you train a dedicated intent classification model for each language you want the bot to support. The bot then detects the language of the input utterance and routes it to the correct language model.
pros
When you train the model adequately with language-specific training expressions, this approach tends to have better intent prediction performance than the translation-based approach. It also has the advantage of limiting possible ambiguity between languages (for example, it won’t confuse four in French with four in English). It makes it easier for models to learn local slang by adding raw utterances from chatter to the training dataset.
cons
However, not all languages have the same quality of training data and pre-trained embedding models. Open-source datasets don’t cover all languages reliably, especially not to minority languages, and not all organizations have the internal expertise to build multilingual training datasets. This creates a training dataset imbalance — the model works well in high-resource languages but not so well in low-resource languages.
Similar to translation-based models, language-specific models are also sensitive to language detection performance. This adds another layer that needs to be monitored and improved over time. Feedback mechanisms need to be in place for both systems.
The major shortcoming of building a language-specific NLU model is the level of investment required to build and maintain it. Each language needs to be trained from scratch, and each model needs to be maintained and improved independently. A German model won’t benefit from the training provided to the Spanish model.
This requirement puts a dent in the scaling ambitions of brands. It also hinders exploration into new language markets where brands don’t have internal resources to prospect a whole new language.
language-agnostic NLU
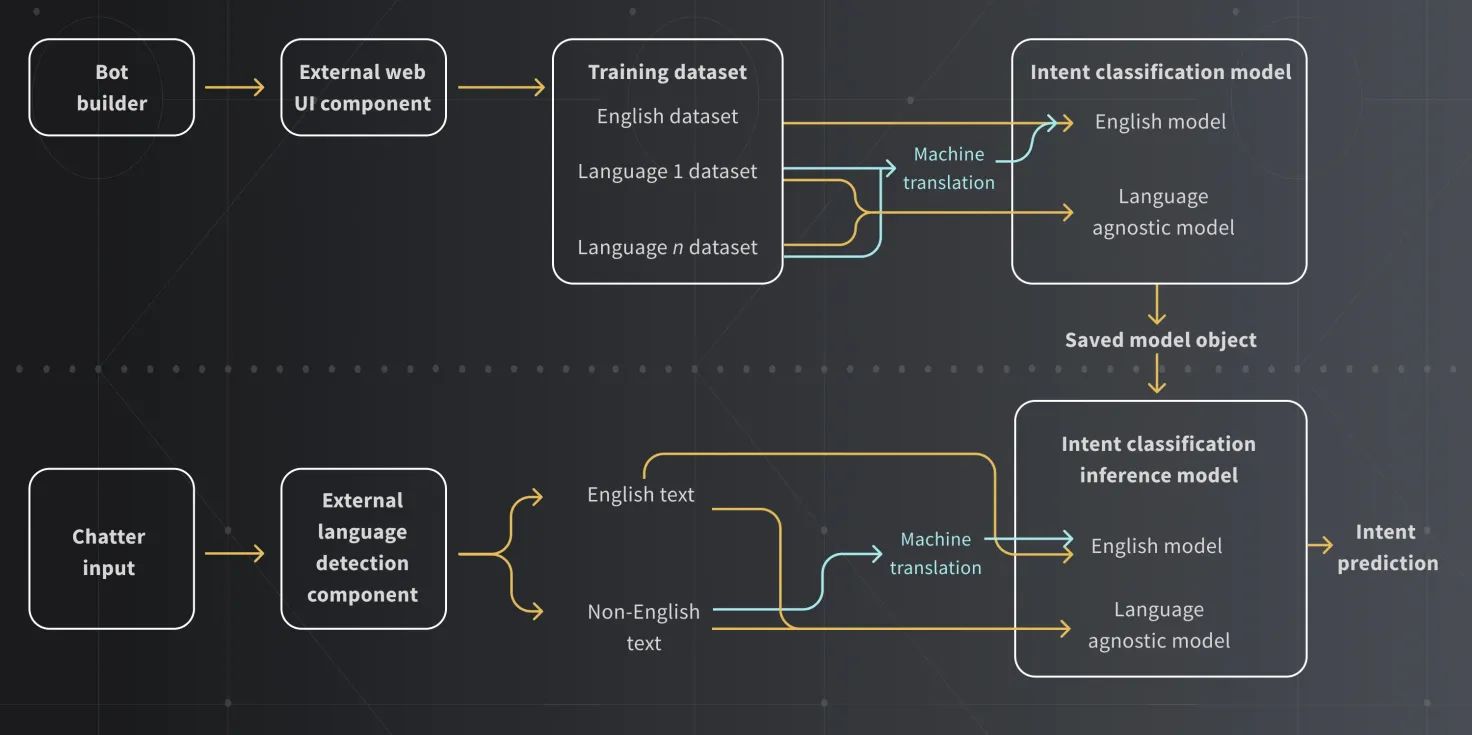
Recent developments in machine learning and large language models have created a new class of embedding models called language-agnostic. The idea behind language-agnostic models is that the text in the speaker’s language gets converted directly into a machine representation in the embedding model. In other words, the translation step is learned by the language model, removing the dependency on external machine translation services.
A language-agnostic model is trained to map input questions — no matter what language they are written in — into a shared semantic or “meaning space." In this space, all questions with the same semantics are located near each other. The language-agnostic model is trained on billions of translation pairs. And each pair is made up of two sentences from different languages that have the same meaning.
pros
This model can understand chatter utterances across many languages. It can also learn from multilingual training data without relying on a translation engine. We can leverage the semantic similarity between languages and make the bot respond to questions more accurately by limiting the noise induced by MT engines.
And the approach is scalable; you can build it once and deploy it everywhere. It removes friction when improving chatbots with multilingual feedback, and it’s resource-efficient. You only need to update and optimize a single source of truth, unlike language-specific NLU models, where each model needs to be maintained independently.
cons
An unfortunate downside of language-agnostic models is that, due to improved multilingual capacity, they lose a bit of performance in English compared to monolingual models. This is expected — monolingual models tend to overfit tasks in a specific language, whereas language-agnostic models must perform across a wide range of languages.
Also, similar to the language-specific model, they tend to perform more poorly on lower resource languages — those with relatively less data available for training conversational AI systems.
But these limitations can be avoided by adopting an ensemble approach, which is what Ada opted to implement. Stay tuned — more on that below.
summary
Language-agnostic models have the potential to remove many obstacles found in building and scaling multilingual bots. Here’s a summary of the three approaches, the effort-level required to build, and the output performance.

the ensemble approach
Of all the experiments we ran to classify the intent of chatter utterances, an ensemble of two distinct models — a core monolingual ML model and a language-agnostic ML model — yielded the best intent prediction performance. This unified ML system takes a weighted average of the prediction values of both models to make its final prediction.
When comparing the performance of an ensemble model against other models, there’s a considerable improvement both in the core language (English in this case) and all the other languages.
In one of our experiments, we compared the intent classification performance of a translation-based model, a language-agnostic model, and an ensemble of both models. This experiment was run on a dataset of 7148 utterances divided into 741 intents. The dataset was extracted from 12 active bots and is available in 10 languages.
Combining a translation baseline and a language-agnostic model led to a 6.2% net improvement in the F1 score across all languages. In the below, the F1 score represents the balance between the precision and recall of the intent classification task.

ada makes support effortless
Discover Ada’s industry-leading NLU model and AI technology that empowers brands to treat everyone like a VIP.
Learn more