
Guide to interviewing AI Agents
What makes an AI Agent different from the typical chatbots you’ve used in the past? Is the impact on ROI really that high?
Learn More

In March 2016, a peculiar Twitter account emerged on the scene. The account tweeted a lot, with almost 100,000 tweets fired in its first day on the platform. You probably already guessed it — the “user” behind this account was actually a bot named Tay, powered by machine learning (ML). Tay was developed to interact with human Twitter users aged 18 to 24 and to learn from them.
At first glance, a Twitter bot exchanging pleasantries and engaging in innocuous banter with other users may seem harmless. And while Tay’s tweets were initially wholesome and playful, its behavior quickly changed as it started adapting to the discriminatory and harmful content it received from other users. It proceeded to partake in these harmful, biased perspectives and was ultimately taken down within 24 hours.

Today, many of our daily actions and interactions with technology are powered by ML. Research teams have applied it to beat world champion Go players , generate human-like texts , and solve the protein structure prediction problem — a problem that stumped scientists for decades. Its application is used across the board at an unprecedented scale, with notable impacts like predicting hospital inpatient risk of death or powering self-driving vehicles.
ML algorithms (along with the training data) are also the engine that powers generative AI and its applications — think ChatGPT and DALL-E — and some of our more everyday interactions, such as the ranking of content we see on social media, voice assistants, and conversational AI.
But in some generative AI applications like Tay, algorithmic bias can creep in — and it can quickly lead to unexpected and undesirable outcomes. But how does this happen, and how do we, as machine learning scientists and engineers working to automate customer support resolutions while delivering VIP experiences, avoid this? Let’s start by defining what an algorithm is and exploring how and where bias comes into play.
Computer algorithms have been around for centuries. In fact, the first computer algorithm is thought to be written by Ada Lovelace in the 1800s — for whom Ada is named after!
Simply put, computer algorithms contain sets of instructions that allow a computer to process input data into useful outputs or actions, like controlling elevators and optimizing traffic flow . Traditional algorithms contain explicit sets of instructions, handwritten by a programmer using programming languages. Generally speaking, traditional algorithms are deterministic, meaning their behavior can be fully tested and understood before use in the real world.
In recent years, improvements in computer hardware and the accumulation of massive amounts of digital data have popularized another prominent family of computer algorithms, sometimes referred to as Software 2.0 . These are “learning” algorithms that use data to build predictive models, and the models are then used to build generative AI applications . This means their behavior is largely dictated by the data that was used to “train” them.
Over time, we’ve learned that these “self-learning machines” actually thrive on computational power and data, creating new opportunities in spaces that were previously untenable using traditional algorithms. With the ability to learn effectively from data, ML models can learn to solve a variety of tasks and allow computer scientists and engineers to shift their focus from building explicit algorithms that solve specific tasks to building general learning algorithms.
But the ability to learn from data doesn’t ensure that learning algorithms create models that can be trusted to perform in the real world. You’ve no doubt heard about Google Bard’s 100 billion dollar mistake , or Microsoft Bing arguing with a user over factually incorrect information, or any of the other “LLM fails” that make the rounds every now and then.
“All models are wrong, but some are useful.”

Algorithmic bias refers to when an algorithm systematically performs or behaves preferentially (or at times, behaves negatively) towards a subset of its intended users. This can happen under a few circumstances.

2. The data used to train a ML model is biased. A model is built to represent the data it’s trained on by using observed historical patterns to parse and understand future unseen data. This framework can lead to the model using any and all differentiating factors within the training data, and in extreme cases, overfit to non-generalizable patterns. Biased training data can arise when improper assumptions are made when sampling or preprocessing the data, something that is usually within the programmer’s control. But training data can also contain latent bias outside of a programmer’s control due to existing, but unjust, sociohistorical bias.
If biased patterns or associations exist within the training data, an ML model may leverage these to make future predictions. In conversational AI, biased language models can generate discriminatory text (as seen in Tay) or biased text classification predictions .
Data-driven algorithms can provide a false sense of objectivity, particularly to end users who don’t have a good understanding of their pitfalls. For example, it’s easy to conclude (falsely) that a decision made by an ML model is more objective than one made by an individual judge or group of jurors — after all, the model has been trained on millions of data points while the judge and jury are humans prone to err due limited cognitive capacity or personal biases.
But in the case of COMPAS, a recidivism risk assessment system used in the US criminal justice system, decades of social injustice etched into the historical data contributed to the creation of a racially-biased algorithm .
Because ML models are largely influenced by training data, even the flaws in a dataset can be used by a model to learn what behavior to imitate. This is obviously problematic, as samples of data are not guaranteed to represent the truth, and many data generating processes themselves are actually discriminatory and contain systemic biases.
These biases aren’t new either, they’ve been plaguing data scientists for decades in one form or another — such as the misdiagnosis of AIDS as “GRID” in the 1980s, or the flaw of averages that caused hundreds of jet accidents in the 1940s . ML models are just the latest way they’ve manifested.
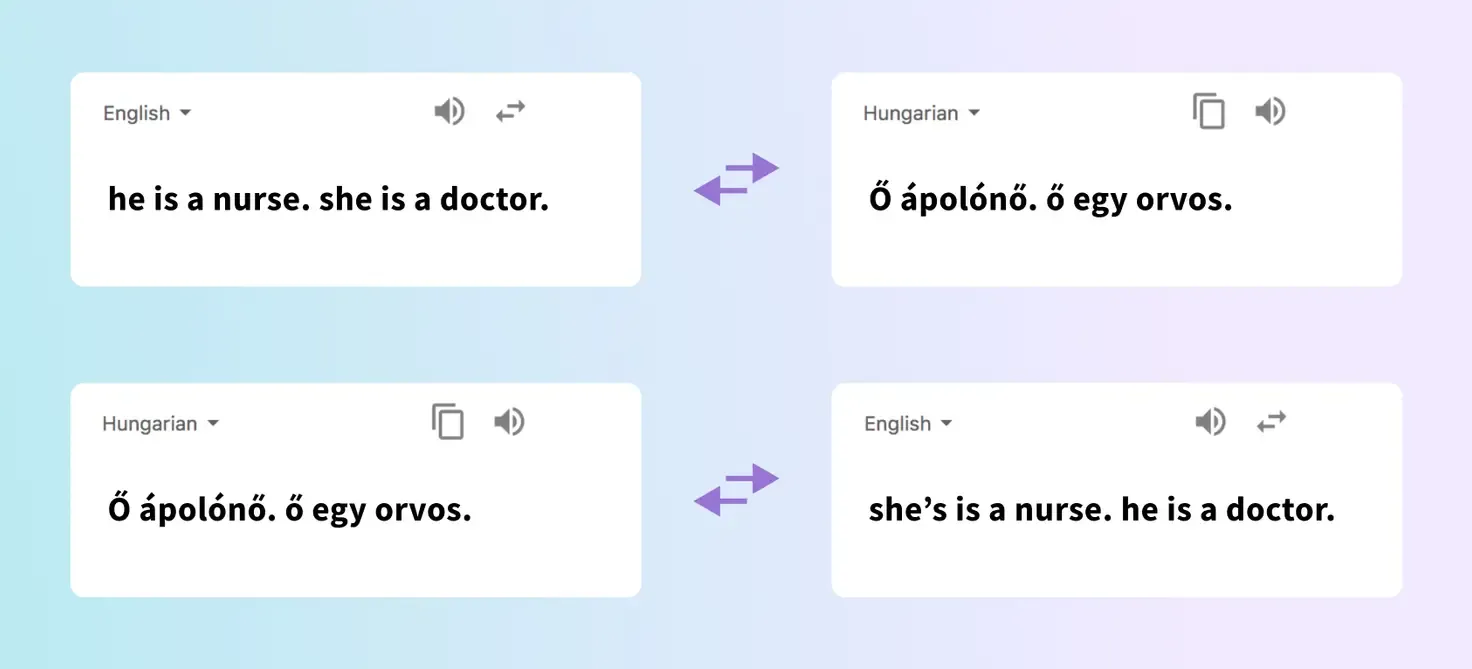
We also see bias encoded into language translation models. The below example shows that when the English sentence “he is a nurse. she is a doctor” is translated to Hungarian and then back to English on Google Translate, the genders swap. Google has worked to address this by providing a workaround for some languages .
Recent trends in ML research show exponential growth on both the size of the models being developed, as well as the datasets used to train these models. But the challenge with the “bigger is better” approach is that it becomes increasingly difficult to ensure high data quality as data volume increases. Larger models have higher capacity to encode more information, sure, but they also have higher capacity to encode bias present in the data .
Even text-generation models like ChatGPT have been shown to generate harmful and discriminatory text .
Despite the drawbacks of algorithmic bias, ML technologies have the ability to dramatically improve life as we know it, from accelerating medical breakthroughs to dramatically reducing customer support wait times. To do so responsibly and effectively, there are some general rules that builders of ML-powered applications should keep in mind.
4. Consider applying techniques. If the data contains sensitive information that is irrelevant to the task, data redaction techniques can preserve the anonymity and privacy of your user-collected data. And it can remove potentially spurious correlations. For example, removing personal health information like medical conditions is helpful in ensuring that your model does not use health disparities to make future predictions when it’s not warranted.
5. Continue to monitor key metrics for your application. Monitoring the model allows you to proactively detect issues (and fix them) as they arise, so that your initially effective and equitable model remains that way. When it comes to monitoring for algorithmic bias, the corresponding monitoring metrics must be specific enough to assess for bias. Subgroup-specific error metrics will give a better indication than aggregate performance.
6. Include a human-in-the-loop or provide a human fallback. This is particularly important when using ML-powered applications to make decisions in high-stakes scenarios. In any case, this is a beneficial addition to your process; human subject matter experts can provide invaluable insights into the decision-making process, which can be used to improve your application.
ML algorithms continue to expand scientific and technological boundaries. And they enable the scalable automation of tasks in seemingly magical ways — conversational AI that remembers who you are and proactively guides you to the next step, to a product you might be interested in, or reminds you about a promotion that rewards you for your brand loyalty.
As we progress further along the AI revolution , the prevalence of algorithmic decision-making will continue to grow. We increasingly put our trust in algorithms to conduct higher-stakes decision-making, so it’s critical that the construction, application, and maintenance of such algorithms be done responsibly and ethically in order to mitigate the harmful effects of algorithmic bias.
Evolve your team, strategy, and tech stack for an AI-first future.
Get the toolkit


